

This post is also available in:
![]() Français (French)
Français (French)
You’ve probably already spoken with an artificial intelligence (AI), whether via ChatGPT, a voice assistant, or an AI integrated into an app. You type a sentence, press “Send”… and a response pops up, often impressive, sometimes even mind-blowing.
But what happens between the time you send your (prompt) message and the time the AI responds?
In this article, we’ll take you on a simplified and educational journey to the heart of an AI’s brain. We promise, you don’t need a math major to understand. Follow the guide.
📥 Step 1: You write a “prompt” (a request)
It all starts with you.
👉 Example:
“Give me a simple chocolate cake recipe.”
This message is called a prompt. It’s an instruction, a question, or a request to the AI. But at this point, it’s just plain text.
🧬 Step 2: The text is encoded into numbers (tokenization)
AIs don’t directly understand text like we do. They don’t see letters or words, but numbers.
How does it work?
The AI uses an encoder (called a tokenizer) to convert the text into “tokens”: units of meaning that can be words, syllables, or word fragments.
👉 Example: The prompt
“Give me a simple chocolate cake recipe.”
can be transformed into something like:[2049, 1098, 1325, 5011, 67, 7823, 1250, 32, 9003]
Each number represents a piece of a word or a whole word.
📌 Why numbers?
Because language models are mathematical machines. They only work with numerical vectors. Therefore, words must be translated into numbers before they can be processed.
🧠 Step 3: The AI predicts the rest word by word
Once the prompt is encoded, we enter the heart of the system: the language model, an enormous mathematical machine based on artificial neurons.
AI doesn’t know how to “answer” in the human sense of the word. It guesses word by word what should come next. This is statistical prediction.
Concretely:
- She receives the prompt tokens.
- It calculates (using millions, even billions of parameters) what the probability is of each possible word to follow.
- She chooses the most likely (or one word among the most likely, depending on the model’s temperature).
- She adds this word to the sequence, and starts again with this new sentence.
👉 Example: It might start by generating:
“Here’s a simple recipe for a delicious chocolate cake:”
Then:
“Ingredients: 200g dark chocolate, 100g sugar…”
And it continues like this until the answer is deemed complete.
🧠 Zoom in on the model: a “sentence completion machine”
The operation is based on a simple but powerful principle:
Complete the text by guessing what comes next.
This mechanism is made possible by a very powerful type of neural network called Transformers.
Each artificial neuron doesn’t understand anything about language, but by stacking layers of calculations, AI learns to:
- recognize grammatical structures;
- understand the context;
- imitate writing styles;
- manage encyclopedic knowledge.
…
⚠️ Important: The AI doesn’t actually understand what you’re saying. It statistically mimics what a human might say to a similar sentence, based on the billions of texts it has “read” during training.
💾 Step 4: The AI generates the response… still in tokens
When the AI is done predicting the response tokens, it keeps them as numbers.
👉 For example, the answer might be something like:[4501, 2199, 1325, 1055, 9003, 11, 9021, 221]
It is therefore necessary to perform the reverse operation of the initial encoding to recover readable text.
🔁 Step 5: Decoding and Display
It is the inverse encoder (called decoder) which transforms the generated tokens into text.
👉 Here’s our text answer:
“Here’s a simple recipe for a delicious chocolate cake:…”
This is the final text that is displayed in the user interface (chat, console, mobile application, etc.).
🔄 What does the AI do if I correct or clarify my question?
The AI treats the entire conversation history as a single long text.
It reviews the previous context, adds your new instruction, and then repeats the process:
- Tokenization of the full message (old + new).
- Calculation of the most probable sequence.
- Word-by-word generation of the response.
- Decoding the result.
🧮 And all this takes… less than a second?
Yes. On powerful servers or local machines with a good GPU, this process takes a few milliseconds to a few seconds, depending on:
- the size of the model (GPT-2, GPT-3, LLaMA, Mistral, etc.);
- the length of the response;
- the complexity of the issue.
🔐 Where does my data go? (Bonus: confidentiality)
When using cloud AI (ChatGPT, Bard, etc.), your prompts are sent to remote servers. This can raise issues such as:
- confidentiality,
- data ownership,
- security (leaks, hacks),
- GDPR compliance.
Possible solution: use a local AI, such as OLLAMA or LM Studio. (We talk about it here)
Benefits :
- Your data never leaves your machine;
- No network dependency;
- You remain in complete control.
🧵 Visual Recap: A Prompt’s Journey
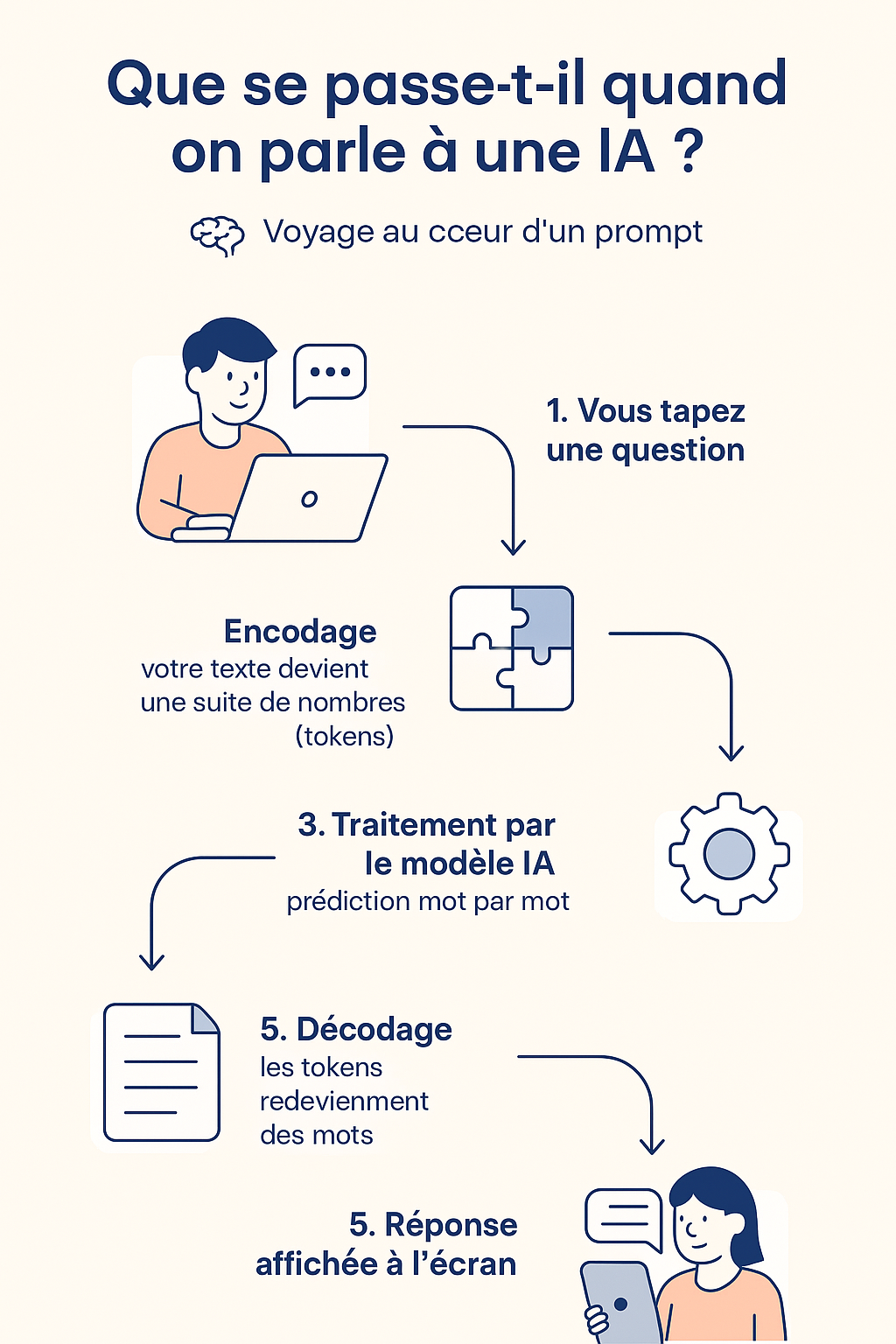
✨ Conclusion: (almost) understandable mathematical magic
While AI may seem like magic, it relies on a series of well-defined mathematical operations. Every time you interact with a language model, a digital dance takes place behind the scenes to produce a coherent, rapid, and often impressive response.
And now that you know what’s going on behind the screen…
👉 Maybe you’ll see your prompts in a different light!
